

系统介绍
本系统主要使用了Flume、kafka、Spark、Mysql数据库、python的Django框架以及echarrts来实现整个功能

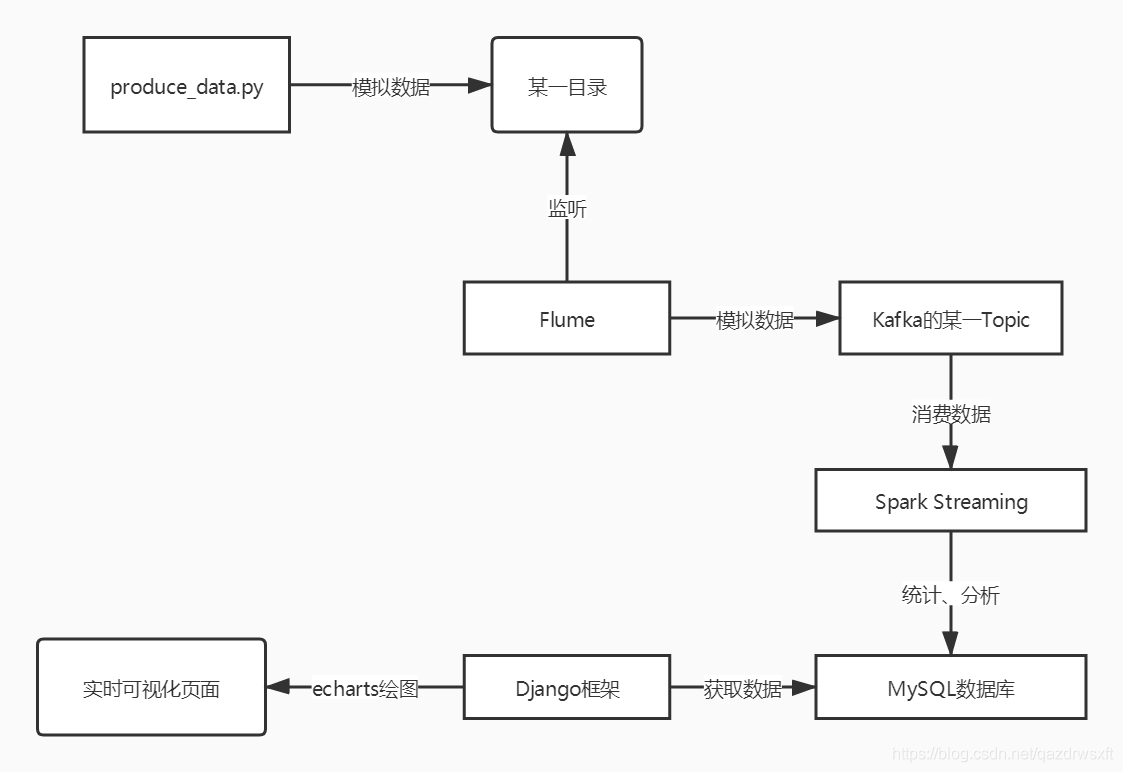
本系统按照实现功能不同,分为两个模块,一个是获取及处理流数据模块,一个是实时可视化模块 对于获取及处理流数据模块,本系统利用Flume监听一台虚拟机上的目录,将目录中的数据传到Kafka的某一Topic中,而后利用SparkStreaming来作为这一Topic的消费者,来实时分析数据并将分析统计结果存入到Mysql数据库中
而实时可视化模块则用Django框架固定时间间隔从数据库中取出所需数据,结合echarts画出相应的图,最后展示在页面上,实现固定时间间隔的页面刷新以及近似实时可视化
系统的框架大致如下,由于没有数据源,所以此处我自己编写了一个程序来模拟产生数据
环境配置及相关命令
Flume相关配置
spooldir.conf
启动Flume任务时,需要指定相应的conf文件,来确定Flume的source(从哪里取数据)、sink(数据发送到哪里)
此处的这个conf文件设定source为spooidir类型并指定监听的spooDir路径;指定sink为kafka并指定相应的Topic和kafka主机及端口号等信息
此处设定的spoolDir因为没有,所以需要提前创建,而kafka对于sparkstreaming_1这一topic会在kafka配置部分进行创建
kafka相关命令
在spooldir.conf中,我指定了这个conf对应的任务的sink为kafka的sparkstreaming_1这一Topic
对于kafka部分,需要在3台虚拟机上启动kafka(首先保证zookeeper都已经启动)
然后再创建sparkstreaming_1这一topic
Django相关命令
Django部分,主要就是数据库的迁移部分,首先在models.py中指定相应的表结构,并在setting.py中指定数据库的相关信息
models.py中设定数据库的代码如下所示