




网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以戳这里获取
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
damage_skill1, damage_skill2 = damage(20, 30) #序列解包 print(damage_skill1, damage_skill2)
序列解包 元素的个数要相等 参数 1.必需参数 2.关键字参数
add(y=3,x=2)
3.默认参数 定义函数的时候直接在形参之中赋值
**注:**必须参数必须全部放在前面,默认参数必须全部放在后面
def add(x, y=2): result = x + y return result
类与对象
class  类的定义:
类的定义:
class Student(): name = ‘’ age = 0
def print_file(self): print('name = ’ + self.name) print('age = '+str(self.age))
**注意:**类里面的函数一定要加self,且调用函数变量也是通过self。
类的实例化:
student = Student()
注意: Python没有new关键字,直接使用类名加括号的方式完成;类的实例化。
类的引用:
from test4 import Student
构造函数
类变量与实例变量
print(Student.name),通过类名.类变量访问实例变量。
class Student(): #类变量 name = ‘小七’ age = 0
def __init__(self, name, age): #构造函数变量 self.name = name self.age = age print(“Student”)
def do_homework(self): print('name = ’ + self.name) print('age = ’ + str(self.age)) print(‘do homework!’)
#实例变量 student = Student(‘李小璐’, 18) print(student.dict) student.do_homework()
{‘name’: ‘李小璐’, ‘age’: 18} name = 李小璐 age = 18 do homework!
self与实例方法
- self几乎相当于this。
- 显示指出,显胜于隐。
- 实例方法的特点:第一个参数要传入self。
类方法
通过注解(装饰器)的方式声明类方法:@classmethod
@classmethod def plus_sum(cls): pass
静态方法
通过注解(装饰器)的方式声明静态方法:@staticmethod
@staticmethod def add(x, y): pass
成员的可见性
使用global关键字定义全局变量 加上双下划线就可吧成员变为私有的,相当于private。Python内部实际上是将定义的私有变量改了名称,变相的私有化。
__score = 60 def __add(x, y): pass
通过print(student.dict)看一下: {‘name’: ‘李小璐’, ‘age’: 18, ‘_Student__score’: 100} 可知我们定义的“__score”变量被系统更名为“_Student__score”,这时我们访问_Student__score是可以访问的到的。、 整个类的结构如下:
class Student(): name = ‘小七’ age = 0 __score = 60
def __init__(self, name, age): self.name = name self.age = age print(“Student”)
def set_score(self, score): self.__score = score
def get_score(self): return self.__score
def do_homework(self): print('name = ’ + self.name) print('age = ’ + str(self.age)) print(‘do homework!’)
@classmethod def plus_sum(cls): pass
@staticmethod def add(x, y): pass
student = Student(‘李小璐’, 18) print(Student.name) student.do_homework() student.set_score(100) print(student.get_score()) print(student.dict) print(Student._Student__score)
Student 小七 name = 李小璐 age = 18 do homework! 100 {‘name’: ‘李小璐’, ‘age’: 18, ‘_Student__score’: 100} 60
继承
避免定义重复的方法,重复的对象
class Animal(): speak = ‘’
def __init__(self, speak): self.speak = speak
def get_speak(self): return self.speak
def eat(self): print(‘Animal eat’)
class Cat(Animal): name = ‘’
def __init__(self, name, speak): super(Cat, self).init(speak) self.name = name
def get_name(self): return self.name
def eat(self): super(Cat, self).eat() print(‘Cat eat’)
cat = Cat(‘花花’, ‘喵喵喵’) print(cat.get_name() + ‘正在说:’ + cat.get_speak()) cat.eat()
花花正在说:喵喵喵 Animal eat Cat eat
Car继承了Animal,用super关键字,可以调用父类的构造方法,也可以调用父类的实例方法。
正则表达式介绍
正则表达式是一个特殊的字符序列,一个字符串是否与我们这样的字符序列相匹配。 快速检索文本,实现文本的替换操作
- 检查一串数字是否是电话号码
- 检查一个字符串是否符合email标准
- 把一个文本里面指定的单词替换为另一个单词
引入re模块
import re
例如,找出字符串中的所有数字
import re
a = ‘w3e45rb6gh6j87’ r = re.findall(‘d’, a) print®
[‘3’, ‘4’, ‘5’, ‘6’, ‘6’, ‘8’, ‘7’]
元字符’d’匹配一个数字字符,
字符集
import re
a = ‘abc, acc, adc, aec, afc, ahc’
r = re.findall(‘a[bf]c’, a) print®
r = re.findall(‘a[b-f]c’, a) print®
[‘abc’, ‘afc’] [‘abc’, ‘acc’, ‘adc’, ‘aec’, ‘afc’]
概括字符集
s:用于匹配单个空格符,包括tab键和换行符; S:用于匹配除单个空格符之外的所有字符; d:用于匹配从0到9的数字; D:用于匹配非从0到9的数字; w:用于匹配字母,数字或下划线字符;[A-Za-z0-9_] W:用于匹配所有与w不匹配的字符; . :用于匹配除换行符之外的所有字符。 链接如下: https://baike.baidu.com/item/正则表达式
数量词
在表达式后面加个大括号{}
import re
a = ‘python10java123php12c’
r = re.findall(‘[a-z]{3,6}’, a) print®
[‘python’, ‘java’, ‘php’] 由于Python默认贪婪的模式,会尽可能的匹配更多,当匹配到’pyt’的时候满足条件,但是由于贪婪还会继续匹配后面的’hon‘,直到不满足条件为止(字符是否在a-z之间,长度是否超过6).
‘*’星号前面的字符可以匹配0次,甚至n次
‘+’加号前面的字符可以匹配1次,甚至n次
‘?’问号前面的字符可以匹配0次,甚至1次
import re
a = ‘pytho00python11pythonn22’ r = re.findall(‘python*’, a) print® r = re.findall(‘python+’, a) print® r = re.findall(‘python?’, a) print®
[‘pytho’, ‘python’, ‘pythonn’] [‘python’, ‘pythonn’] [‘pytho’, ‘python’, ‘python’] 结果第三行,第三个单词怎么会出现python呢,?不是匹配0次n,或者1次n吗。原因是将pythonn后面的一个n截取了,在匹配pythonn时匹配到python的时候,满足条件,就自动输出了,没有理会后面的n。
边界匹配符
匹配一个QQ号是否是4-8位的
shift+6 ^(从字符串的开头开始匹配) shift+4 $(从字符串的末尾开始匹配)
qq = ‘123456789’ print(re.findall(‘^d{4,8}$’, qq))
组 :一个括号就是一个组
查看一个字符串中是否包含5个Python
st = ‘PythonPythonPythonPythonPythonPythonPython’ print(re.findall(‘PythonPythonPythonPythonPython’, st)) print(re.findall(‘(Python){5}’, st))
匹配模式参数
如,忽略大小写 re.I、re.S 用findall()的第三个参数
a = ‘ABC’ r = re.findall(‘abc’, a, re.I) print® r = re.findall(‘abc’, a, re.I | re.S) print®
re.sub正则替换
a = ‘PythonC#PHP’ r = re.sub(‘C#’, ‘Java’, a, 1) print®
PythonJavaPHP 将字符串a中的C#替换为Java,且只替换1次,要是改为0(默认),则无限替换。可以用一个函数替换Java做为参数。
把函数作为参数传递
找出字符串‘A8C3721D86’中的数字,将小于6的替换为0,大于6的替换为9。
import re
s = ‘A8C3721D86’
def convert(value): matched = value.group() if int(matched) < 6: return str(0) else: return str(9)
r = re.sub(‘d’, convert, s) print®
A9C0900D99
search与match函数
re.match() re.search()
group()分组
s = ‘life is short, i use python, i love python’
r = re.search(‘life(.)python(.)python’, s) print(r.group(0, 1, 2)) print(r.groups())
(‘life is short, i use python, i love python’, ’ is short, i use ‘, ‘, i love ‘) (’ is short, i use ‘, ‘, i love ‘) group(0)对应的是整个字符串的完整的匹配项 group(1)对应的是第一个分组 group(2)对应的是第二个分组
groups()返回的是第一个与第二个分组
常用的正则表达式:
https://www.cnblogs.com/Akeke/p/6649589.html
一种轻量级的数据交换格式,跨语言交换数据
字符串是json的表现形式
符合JSON格式的字符串,叫做JSON字符串
反序列化
导入json模块
import json
import json
json_str = ‘{“status”: 0, “msg”: “登录成功”, “data”:{“id”: 1,“username”: “admin”}}’ data = json.loads(json_str) print(type(data)) print(data)
class ‘dict’ {‘status’: 0, ‘msg’: ‘登录成功’, ‘data’: {‘id’: 1, ‘username’: ‘admin’}} 可以看到Python的json.loads(json_str)函数,将json字符串转换成了字典(dict)类型
JSON数据类型所对应的Python的数据类型如下: 
序列化
JSON、JSON对象与JSON字符串 JSON是一种轻量级的数据交换格式,跨语言交换数据。
符合JSON格式的字符串,叫做JSON字符串,字符串是json的表现形式。
JSON对象是相对于js来说的。概念太模糊,大概把JSON解析出来的数据封装成的对象就成为JSON对象吧。
枚举其实是一个类
从枚举模块导入枚举类(Enum或IntEnum) from enum import Enum
from enum import Enum
class VIP(Enum): RED = 1 YELLOW = 2 GREEN = 3
print(VIP.YELLOW) print(VIP.YELLOW.value) print(VIP.YELLOW.name)
for v in VIP: print(v)
VIP.YELLOW 2 YELLOW VIP.RED VIP.YELLOW VIP.GREEN
所有枚举类型,都是Enum的子类。
枚举类型、枚举的名字、枚举的值
枚举的比较 不可以做大小比较,但是可以做等值(身份)的比较。
遍历有别名的枚举:
class VIP(Enum): RED = 1 YELLOW = 2 YELLOW_ALIAS = 2 GREEN = 3
for v in VIP.members.items(): print(v)
(‘RED’, <VIP.RED: 1>) (‘YELLOW’, <VIP.YELLOW: 2>) (‘YELLOW_ALIAS’, <VIP.YELLOW: 2>) (‘GREEN’, <VIP.GREEN: 3>)
枚举转换
a = 2 print(VIP(a))
VIP.YELLOW
函数式编程
闭包
在其他语言里面,如Java函数只是一段可执行的代码,并不是对象。在Python里面一切皆对象。 在Python里面可以把一个函数作为参数传递给第一个函数,也可以报函数作为另一个函数的返回结果。
闭包 = 函数+环境变量 一个例子
def curve_pre(): a = 25
def curve(x): return a * x * x return curve
f = curve_pre() print(f(2))
可以看到结果是100,在curve_pre()中return curve的同时不仅把curve(x)函数返回,而且把curve(x)函数的闭包也返回,所以在外部更改a的值,结果不变。
origin = 0
def factory(pos): def go(step): nonlocal pos new_pos = pos + step pos = new_pos return new_pos return go
tourist = factory(origin) print(tourist(2)) print(tourist(3)) print(tourist(6))
2 5 11
nonlocal关键字标明了pos不是局部变量。
匿名函数
使用关键字lambda 定义匿名函数。 lambda 参数: 表达式
def add(x, y): return x+y
print(add(1, 2))
f = lambda x, y: x+y print(f(1, 2))
3 3
注:三元表达式。
- 其他语言(java, c) x > y ? x : y
- Python 条件为真的时候返回的结果 if 条件判断 else 条件为假时的返回结果
map
map方法 map(方法,序列) 对传入的序列的每一个对象,都执行方法。
map与lambda
list_x = [1, 2, 3, 4, 5, 6] r = map(lambda x:x*x, list_x) print(list®)
[1, 4, 9, 16, 25, 36]
reduce
reduce连续计算,连续执行表达式,将序列中的元素逐个取出,执行函数操作。 引入reduce模块 from functools import reduce
from functools import reduce
list_x = [1, 2, 3, 4, 5, 6] r = reduce(lambda x, y: x + y, list_x) print®
21
实际就是对list_x序列求和,如果把lambda x, y: x + y改为lambda x, y: x * y,则对listx序列求积
filter
过滤 例:过滤掉一个数列中大于50的数
list_x = [10, 45, 54, 22, 53, 63] r = filter(lambda x: True if x < 50 else False, list_x) print(list®)
[10, 45, 22] 注:filter()接收的第一个参数的函数返回值为bool类型。
装饰器
感觉类似于java的注解 修改项目业务功能的时候,对修改是封闭的,对扩展是开放的。
*args表示可以接受任意多个参数。 **kw可以接受任意多个关键字参数。
import time
def decorator(func): def wrapper(*args, **wk): print(time.time()) func(*args, **wk) return wrapper
@decorator def f1(func_name): print(‘This is f1’ + func_name)
@decorator def f2(func_name1, func_name2): print(‘This is f2’ + func_name1) print(‘This is f2’ + func_name2)
@decorator def f3(func_name1, func_name2, **kw): print(‘This is f3’ + func_name1) print(‘This is f3’ + func_name2) print(kw)
f1(‘test’) f2(‘test1’, ‘test2’) f3(‘test1’, ‘test2’, a=1, b=2, c=‘kw’)
1517129065.1393104 This is f1test 1517129065.1393104 This is f2test1 This is f2test2 1517129065.1393104 This is f3test1 This is f3test2 {‘a’: 1, ‘b’: 2, ‘c’: ‘kw’}
本质:对html文件进行分析,从而从文本中提取出有用的信息。 爬取斗鱼直播LOL模块下的主播名称及其人气。
from urllib import request import re
class Spider():
url = ‘https://www.douyu.com/directory/game/LOL’
root_pattern = ‘
’ name_pattern = ‘ ’ number_pattern = ‘<span class=“dy-num fr”([sS]*?)’def __fetch_content(self):
headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0’} req = request.Request(url=Spider.url, headers=headers) r = request.urlopen(req)
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
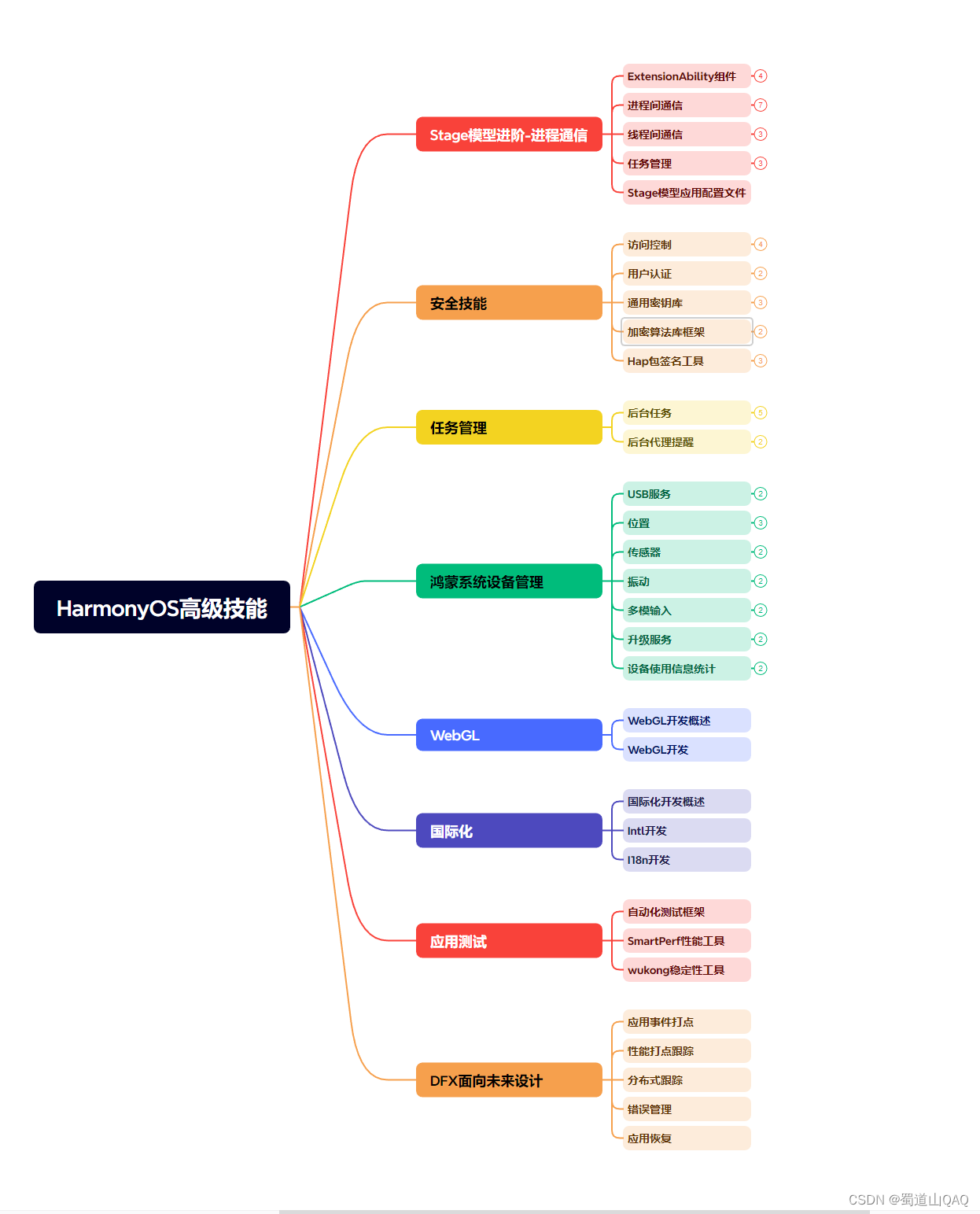


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
需要这份系统化的资料的朋友,可以戳这里获取
span class=“dy-name ellipsis fl”>([sS]*?)’ number_pattern = ‘<span class=“dy-num fr”([sS]*?)’
def __fetch_content(self):
headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0’} req = request.Request(url=Spider.url, headers=headers) r = request.urlopen(req)
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
[外链图片转存中…(img-WPv2XumD-1715276291718)] [外链图片转存中…(img-DG1HvuYl-1715276291718)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!